- Webinar
Obtaining Unit Economics Using Power BI
Demo of reporting on cloud unit economics in a Power BI dashboard.

Demo of reporting on cloud unit economics in a Power BI dashboard.

When and where data modeling fits in each stage of the Azure architecture.

Learn what distinguishes Fabric from conventional cloud architectures. Or not.

Is it still relevant in the modern data environment?
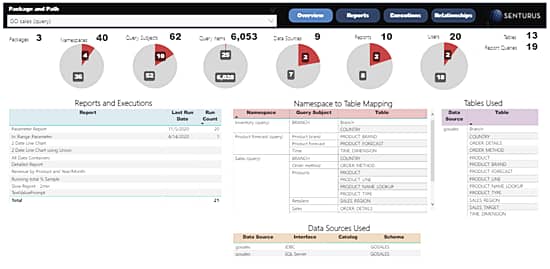
The Migration Assistant eliminates manual Cognos inventory work.
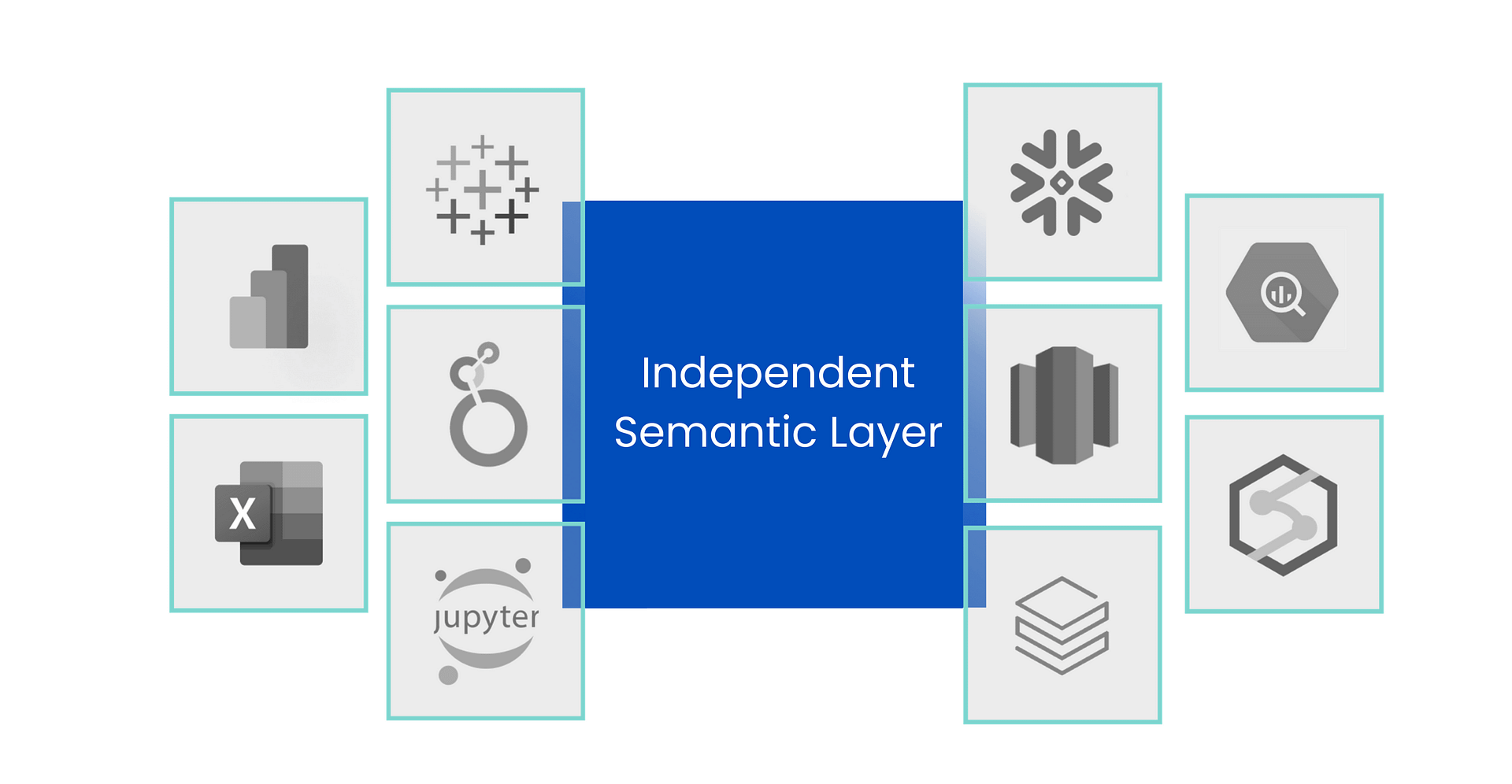
A single source of governed cloud data that can be tapped by Power BI, Tableau, Cognos and Excel.

On-prem, cloud and hybrid deployments. Real-world examples.

Learn about technologies in its data platform.

Access data from multiple cloud and enterprise sources in a customizable BI dashboard.

Drillable Power BI & Tableau dashboard without ETL.

Comprehensive, automated insights that native Cognos tools don’t provide.
Learn how to speed time to analysis.

Industry: Medical devices

Industry: Medical Devices

Industry: Medical Device

Power BI is the most popular tool after the cloud native tools.
